


Why Now: Language Models as a disruptive force on enterprise data systems
For the last two decades, the phrase “Data is the new oil” has served as a common rallying cry for organizations to building robust internal data platforms to unlock business value from their data. We’ve come a long way since then. In particular, we’ve seen two substantial leaps in data:- The rise of elastic, cloud-native infrastructure that makes analytical computation efficient.
- The development of frameworks that let teams build and productize data applications (dashboards, reports) and predictive models (classical ML algorithms).
Data Agents and Workflows as an open, standalone category
The Modern Data Stack (“MDS”) has become the backbone of how organizations store, transform, and visualize data. In many ways, it feels like the natural home for data agents—after all, agents interact with the same components that power analytics today: the BI layer, the ELT layer, and the data warehouse. However, the rise of data agents represents a more fundamental shift that necessitates a decoupling. While data agents can belong to an existing layer of the Modern Data Stack (“MDS”), e.g. as part of a BI tool, the ELT layer, or as part of the data warehouse, we believe that data agents, workflows, and the infrastructure powering them deserves to exist as a separate category. More strongly, not only as its own category, but on its on plane.
Determinism-first design
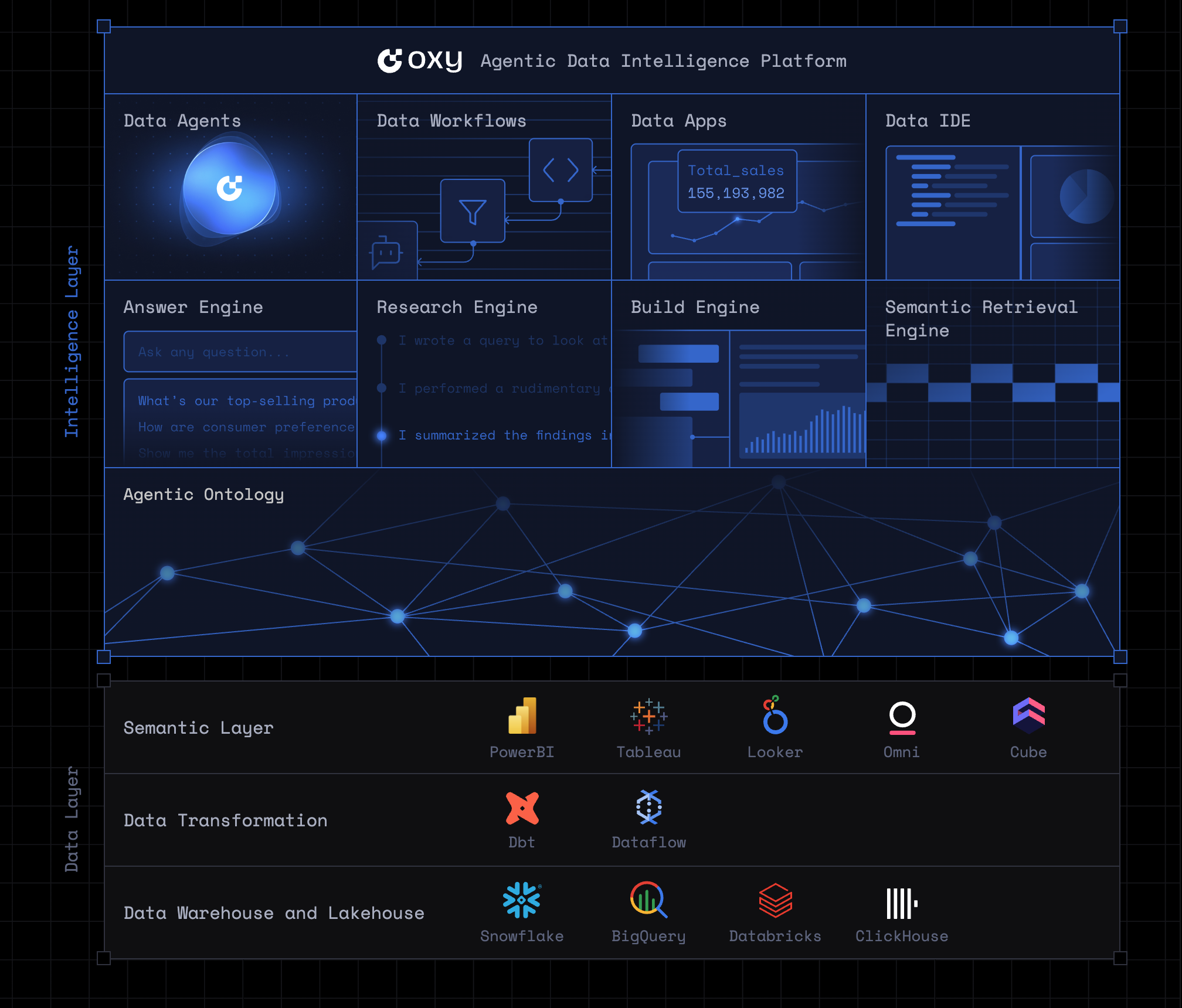
- Ontology infrastructure that provides both the semantic and operational definitions of how to acquire data and to operationalize workflows to get to and end work product
- Composable workflows that can be chained together in a reasoning chain by Data Agents to more deterministically get to most desired outputs.
Accuracy-guaranteed Workflow Automation
